Les hallucinations des modèles LLM : enjeux et stratégies pour les ETI en 2025
Contexte & Enjeux des hallucinations IA pour les Entreprises en 2025
En 2025, l'intégration des Large Language Models (LLM) dans les opérations d'entreprise s'accélère, promettant des gains significatifs en productivité, en qualité de service client et en innovation. Cependant, une problématique majeure persiste avec acuité : les 'hallucinations' des LLM. Ce phénomène, où les modèles génèrent des informations plausibles mais factuellement incorrectes, inventées ou trompeuses, représente un risque critique pour toute organisation.
Pourquoi les hallucinations des modèles LLM sont critiques pour les ETI en 2025
Les hallucinations des LLM ne sont pas de simples erreurs techniques ; elles ont des répercussions directes et tangibles sur le business :
Risques Réputationnels des hallucinations IA
La diffusion d'informations erronées par un LLM intégré à un service client, un outil de communication marketing ou un assistant interne peut gravement nuire à la crédibilité et à l'image de marque de l'entreprise. Un seul incident largement médiatisé peut éroder des années de confiance.
Conformité et Risques Légaux des modèles IA en entreprise
L'utilisation de LLM générant des données inexactes ou biaisées peut entraîner des violations du Règlement Général sur la Protection des Données (RGPD), notamment en matière d'exactitude des données personnelles. De plus, l'AI Act européen, en cours de déploiement, classifie certains usages de l'IA comme 'à haut risque' et impose des exigences strictes en matière de robustesse, de précision et de supervision humaine. Les hallucinations peuvent directement compromettre la conformité à ces régulations, exposant l'entreprise à des amendes substantielles et à des litiges.
Impacts des hallucinations LLM sur les coûts, la qualité et la rapidité
La nécessité de vérifier manuellement les sorties des LLM, de corriger les erreurs, de gérer les plaintes clients ou les problèmes de conformité génère des coûts opérationnels inattendus. Les investissements dans les LLM peuvent ne pas atteindre le ROI espéré si une part significative du temps est consacrée à la 'décontamination' des hallucinations.
Qualité : La fiabilité des informations produites est fondamentale. Des hallucinations peuvent mener à de mauvaises décisions stratégiques, des conseils erronés aux clients, ou des documents internes fallacieux, dégradant la qualité globale des opérations et des services.
Rapidité : Si les LLM sont censés accélérer les processus, la présence d'hallucinations impose des boucles de validation et de correction qui ralentissent les flux de travail, annulant potentiellement les gains d'efficacité initiaux.
La maîtrise des hallucinations n'est donc pas une option, mais une nécessité stratégique pour garantir la fiabilité, la conformité et la performance des systèmes d'IA au sein de l'entreprise.
Comprendre les hallucinations des modèles LLM
Qu'est-ce qu'une hallucination IA ?
Les hallucinations des LLM désignent la tendance de ces modèles à générer des informations qui semblent plausibles et cohérentes, mais qui sont en réalité fausses, inventées, ou déconnectées de la réalité ou des sources fournies. C'est une forme de 'confabulation' où le modèle 'invente' des faits ou des raisonnements.
Les 3 Types d'hallucinations des modèles LLM

On peut catégoriser les hallucinations en trois types principaux :
1. Hallucinations de factualité des LLM
Le modèle génère des informations qui sont objectivement fausses ou contredisent des faits établis. Cela peut inclure des dates incorrectes, des événements qui n'ont jamais eu lieu, ou des données chiffrées erronées. C'est le type le plus évident et souvent le plus dommageable.
2. Hallucinations d'attribution des modèles IA
Le modèle invente des sources, des citations, des références bibliographiques ou attribue des propos à des personnes qui ne les ont jamais tenus. Le contenu peut être factuellement correct, mais son origine est falsifiée.
3. Hallucinations de respect des instructions des modèles LLM
Le modèle ne respecte pas les contraintes ou les instructions données dans le prompt. Il peut ignorer des formats spécifiques, des limites de longueur, des exigences de ton, ou des interdictions de mentionner certains sujets.
Limite structurelle : les modèles LLM sont probabilistes
Il est crucial de comprendre que les LLM sont des modèles probabilistes. Ils génèrent du texte en prédisant le mot suivant le plus probable, basé sur les milliards de paramètres appris lors de leur entraînement sur d'immenses corpus de données. Ils ne 'comprennent' pas les faits au sens humain du terme, ni ne 'raisonnent' logiquement. Leur objectif est de produire du texte qui semble cohérent et naturel, pas nécessairement factuellement exact.
Cette nature probabiliste implique qu'il est impossible d'atteindre 0% d'hallucination. Même avec les meilleures techniques d'atténuation, il existera toujours un risque résiduel. L'objectif n'est donc pas d'éradiquer totalement les hallucinations, mais de les réduire à un niveau acceptable et gérable pour les cas d'usage spécifiques de l'entreprise, en mettant en place des mécanismes robustes de prévention, détection et correction.
Déclencheurs et causes des hallucinations
Les hallucinations ne sont pas aléatoires ; elles sont souvent le résultat de facteurs spécifiques liés à la conception du modèle, aux données d'entraînement, à la manière dont le modèle est interrogé, ou à l'environnement dans lequel il opère. Comprendre ces déclencheurs est essentiel pour les atténuer.
Facteurs favorisant les hallucinations des modèles LLM
Données d'entraînement et qualité des modèles IA
Si les données sur lesquelles le LLM a été entraîné contiennent des erreurs, des incohérences, des informations obsolètes ou des biais, le modèle peut reproduire ou amplifier ces défauts. Un manque de données sur un domaine spécifique peut également pousser le modèle à 'inventer' pour combler les lacunes.
Prompts et requêtes : Impact sur les hallucinations LLM
Un prompt vague, contradictoire ou trop ouvert peut laisser trop de liberté au modèle, l'incitant à générer des informations non fondées. Si l'intention de l'utilisateur n'est pas claire, le modèle peut interpréter la requête de manière inattendue.
Contexte et complexité des modèles LLM
Lorsque le modèle doit traiter un volume important d'informations dans le prompt (contexte), il peut avoir du mal à maintenir la cohérence et la factualité sur l'ensemble du texte, menant à des erreurs ou des oublis.
Absence de sources
Si le LLM n'est pas ancré dans des sources de données fiables et vérifiables (par exemple, une base de connaissances interne), il est plus susceptible de générer des informations sans fondement factuel.
Outils externes et fonctions pour les modèles LLM
Les LLM sont des générateurs de texte. Sans accès à des outils externes (calculatrices, bases de données, API), ils peuvent tenter de 'calculer' ou de 'rechercher' des informations par eux-mêmes, ce qui conduit souvent à des erreurs factuelles.
Paramètres de température des modèles IA
Ces paramètres contrôlent la créativité et la diversité des réponses du modèle. Une 'température' trop élevée (qui favorise la diversité) peut augmenter le risque d'hallucinations, car le modèle est plus enclin à explorer des options moins probables.
Dans quelle mesure les modèles IA hallucinent-ils : benchmarks 2025
Pour comprendre les performances des Large Language Models (LLM) face aux hallucinations, il est essentiel d'examiner les évaluations récentes, notamment celles menées en 2025, qui se concentrent sur des tâches spécifiques. Les taux d'hallucination varient considérablement en fonction du modèle utilisé et de la nature de la tâche.
Objectif de notre sélection de benchmarks IA pour les ETI
Il existe de nombreux bancs d'essai pour les LLM qui testent des aspects particuliers de leurs performances. Certains se concentrent sur les capacités de codage, d'autres font voter les utilisateurs sur la meilleure réponse entre deux modèles anonymes (LMArena). D'autres encore testent les connaissances expertes des LLM et leur capacité à répondre à des questions extrêmement pointues (Humanity last exam's).
Cependant, notre objectif étant d'évaluer dans quelle mesure les LLM peuvent être utilisés en entreprise dans un contexte "agentique" - c'est-à-dire avec une autonomie de décision - nous avons choisi de nous concentrer uniquement sur des benchmarks qui évaluent le traitement d'informations. Cela inclut le traitement via les prompts ou via une technique appelée RAG (Retrieval-Augmented Generation), qui permet aux modèles d'IA de chercher des informations dans une base de données avant de répondre.
Cette approche nous donne une vision plus pertinente de la capacité réelle des LLM à fonctionner de manière autonome dans un environnement professionnel où la précision et la fiabilité des informations sont cruciales.
Présentation de notre sélection de benchmarks IA
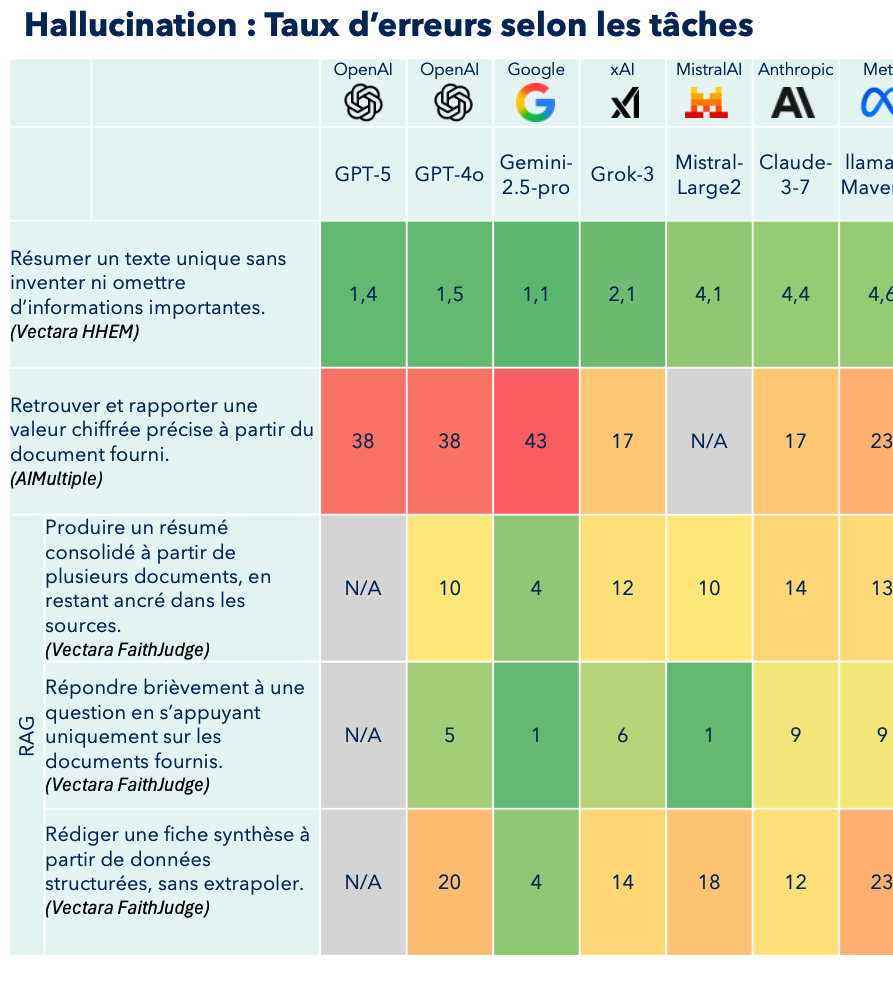
Étude AIMultiple : Retrouver et rapporter une valeur chiffrée
Une étude récente d'AIMultiple, publiée en 2025, évalue la capacité des modèles à retrouver et rapporter une valeur chiffrée précise à partir du document fourni.
Tâche : Répondre à 60 questions basées sur des articles de CNN News. Les questions portaient sur des valeurs numériques précises (pourcentages, dates, quantités), des sujets divers (prix du pétrole, histoire de l'art, recherche scientifique, actualités financières), des relations temporelles et des statistiques difficiles à deviner. L'objectif était de récupérer des chiffres exacts des articles sources.
Source : "AI Hallucination: Comparison of the Popular LLMs in 2025" (AIMultiple, mis à jour le 29 juin 2025).
HHEM : Fidélité à la source
Vectara HHEM : Détection d'hallucinations LLM
Vectara HHEM (Hughes Hallucination Evaluation Model) évalue si les réponses générées par un modèle d'IA sont fidèles aux documents sources. Il détecte les "hallucinations" - quand l'IA invente des informations qui ne sont pas dans les documents de référence.
Source : https://huggingface.co/spaces/vectara/leaderboard
Vectara FaithJudge : Hallucinations à partir de plusieurs documents (contexte RAG)
Comme les entreprises utilisent les modèles LLM dans le contexte de leur business, il est également extrêmement important de tester les performances des benchmarks dans un contexte RAG.
Définition : Le RAG (Retrieval-Augmented Generation) est une technique qui permet aux modèles d'IA de chercher des informations dans une base de données avant de répondre à une question. Au lieu de se fier uniquement à leur mémoire d'entraînement, ils vont d'abord récupérer des documents pertinents, puis génèrent une réponse basée sur ces informations fraîches. C'est comme avoir un assistant qui consulte toujours les derniers documents avant de vous répondre.
Vectara FaithJudge Summary : Résumés fiables des modèles IA
Mesure la qualité des résumés produits à partir de plusieurs documents, en restant ancré dans les sources. Il vérifie si un résumé capture fidèlement les points essentiels des textes originaux sans ajouter d'informations erronées.
Vectara FaithJudge Q&A : Questions-réponses sans hallucinations
Évalue la précision des systèmes de questions-réponses. Il s'assure que les réponses données correspondent bien aux informations contenues dans les documents sources, sans déformation ni invention.
Vectara FaithJudge Data-to-Text : Conversion de données des LLM
Teste la capacité à transformer des données structurées (tableaux, graphiques) en texte naturel. Il vérifie que la description textuelle reflète fidèlement les données sans erreur d'interprétation.
Tous ces benchmarks partagent un objectif commun : s'assurer que l'IA reste fidèle aux informations sources et ne fabrique pas de fausses informations.
Tableau récapitulatif des hallucinations de modèles IA
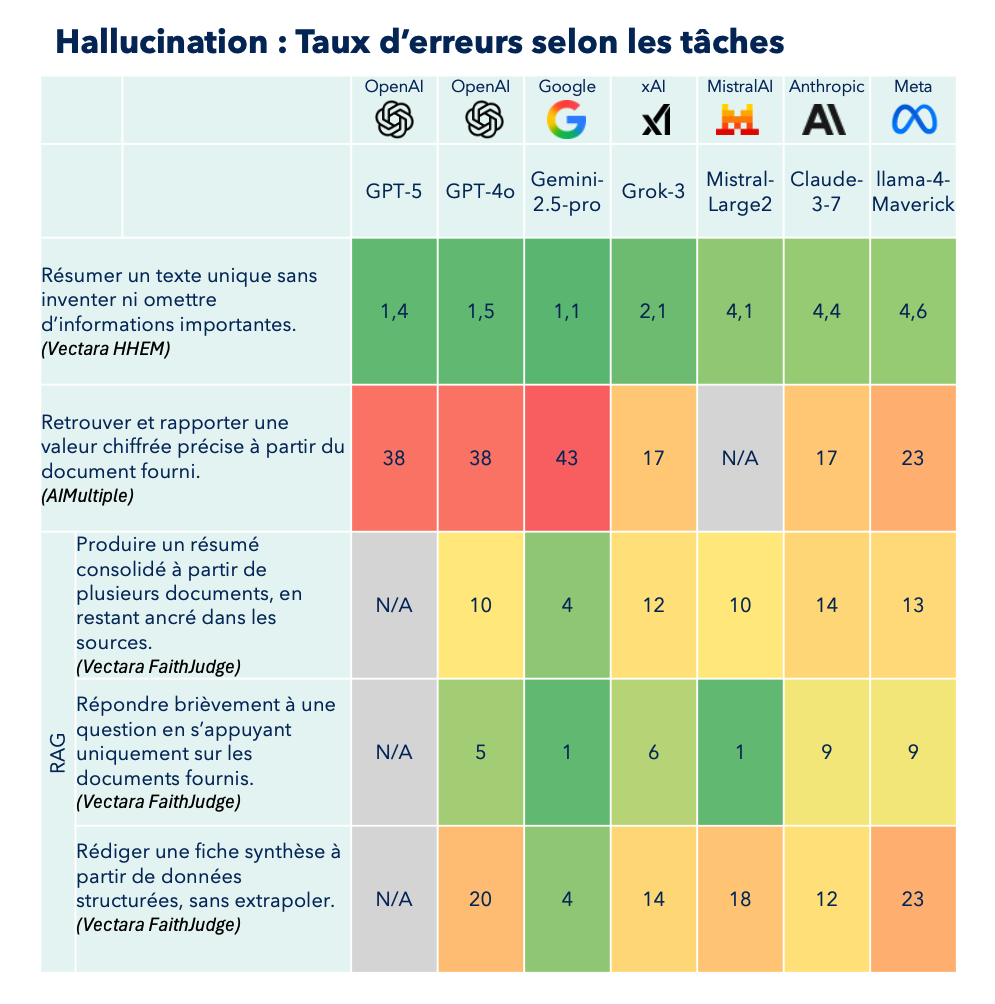
Recapitulatif des taux d’erreurs des LLM les plus populaires
Importance des benchmarks IA pour les stratégies entreprise
Ces benchmarks constituent un outil précieux pour les développeurs qui doivent choisir le modèle d'IA le plus adapté à leurs besoins spécifiques. Chaque LLM possède ses propres forces et faiblesses, et la sélection doit se faire en fonction des objectifs visés.
Il faut toutefois noter qu'aucun LLM n'atteint actuellement (du moins sur ces benchmarks) un niveau de performance "production". En d'autres termes, aucun dirigeant d'entreprise n'accepterait de déployer un LLM qui commet en moyenne 10% d'erreurs, car les conséquences pourraient être catastrophiques.
Heureusement, nous verrons plus loin dans cet article qu'il existe des stratégies permettant aux entreprises d'obtenir des performances bien supérieures sur des cas moins piégeux et mieux documentés.
Ces benchmarks restent néanmoins des guides utiles, même s'ils sont conçus pour pousser les limites des performances des LLM en présentant des cas complexes qui pourraient également troubler des humains.
Mais avant d'explorer ces solutions, examinons les risques concrets que posent les hallucinations pour les entreprises.
Cas d'usage classiques en ETI et enjeux des hallucinations
Pour une ETI, l'intégration des LLM peut transformer plusieurs fonctions clés. Voici trois cas d'usage concrets et les risques d'hallucination associés :
3 cas d'usage des modèles IA pour les entreprises
1. Assistant virtuel LLM pour le service client

Cas d'usage : Un LLM est déployé comme chatbot de premier niveau pour répondre aux questions fréquentes des clients, gérer des demandes simples (suivi de commande, informations produit) et orienter vers un conseiller humain si nécessaire.
Impact des hallucinations IA sur la Relation Client : Si le LLM hallucine des informations sur les produits (prix, caractéristiques, disponibilité), les politiques de retour ou les délais de livraison, cela peut entraîner une insatisfaction client majeure, des litiges, et une surcharge du service client humain pour corriger les erreurs. La réputation de l'entreprise est directement menacée.
2. Génération de contenu marketing avec les modèles LLM

Cas d'usage : Le LLM est utilisé pour rédiger des ébauches de communiqués de presse, des articles de blog, des descriptions de produits, ou des synthèses de réunions internes.
Risques d'hallucinations IA pour la communication entreprise : Des hallucinations factuelles (chiffres clés, dates d'événements, noms de personnes) ou d'attribution (citations inventées) dans le contenu marketing peuvent diffuser de la désinformation au public, nécessitant des rectifications coûteuses et dommageables pour l'image de marque. En interne, des synthèses erronées peuvent mener à de mauvaises décisions ou à une confusion généralisée.
3. Aide à la décision : analyse documentaire par les modèles IA
Cas d'usage : Un LLM est entraîné sur des documents internes (manuels techniques, rapports de production, contrats fournisseurs) pour aider les équipes opérationnelles à trouver rapidement des informations, résumer des documents complexes ou générer des premières ébauches de procédures.
Conséquences des hallucinations LLM sur les Opérations : Si le LLM hallucine des procédures de sécurité, des spécifications techniques ou des clauses contractuelles, cela peut avoir des conséquences graves : accidents de production, non-conformité réglementaire, ou litiges contractuels. La qualité et la fiabilité des opérations sont directement compromises, avec des risques financiers et humains potentiels.
Stratégies de gestion des hallucinations IA
Approche Multicouche contre les hallucinations des modèles LLM
La gestion des hallucinations nécessite une approche multicouche, intégrant des stratégies à chaque étape du cycle de vie de l'application LLM.
1. Prévenir les hallucinations IA en Entreprise
La prévention est la première ligne de défense, visant à réduire la probabilité d'apparition des hallucinations.
Cadrage des Prompts et Politiques Anti-Hallucination
Des prompts clairs, précis et structurés sont fondamentaux. Ils doivent inclure des instructions explicites sur le format de sortie, le ton, les limites de longueur et les sources à utiliser. L'établissement de politiques d'utilisation claires pour les utilisateurs finaux (ne pas poser de questions sur des sujets sensibles, toujours vérifier les informations critiques) est également crucial.
Schémas JSON : Structuration des Sorties LLM
Pour les cas d'usage nécessitant des sorties structurées (extraction d'informations, génération de données pour une base de données), l'utilisation de schémas JSON permet de contraindre le LLM à générer des réponses conformes à une structure prédéfinie. Cela réduit considérablement les hallucinations de format et les erreurs de suivi d'instructions.
RAG et Sources Autorisées : Ancrage des modèles IA
Au lieu de laisser le LLM générer des informations de sa mémoire d'entraînement, le RAG consiste à lui fournir des documents pertinents et vérifiés (base de connaissances interne, documents officiels) avant la génération de la réponse. Le LLM est alors instruit de ne répondre qu'en se basant sur ces sources. C'est la méthode la plus efficace pour réduire les hallucinations factuelles.
Outils Externes pour les modèles LLM
Les LLM sont de mauvais calculateurs et de mauvaises bases de données. Pour les tâches nécessitant des calculs précis, des recherches dans des bases de données structurées ou l'exécution de logiques complexes, le LLM doit pouvoir appeler des outils externes (API, fonctions Python, bases de données). Cela garantit l'exactitude des informations numériques et factuelles.
Contrôle de Température des modèles IA
Le paramètre de température du LLM contrôle la créativité de la réponse. Pour les applications où la factualité est primordiale, une température basse (proche de 0) est recommandée pour rendre les réponses plus déterministes et moins sujettes à l'invention.
Filtres de domaine pour les LLM Entreprise
Implémenter des filtres en amont pour s'assurer que les requêtes restent dans le domaine de compétence du LLM et des sources de données disponibles. Si une requête sort du périmètre, le système peut refuser de répondre ou la rediriger.
Fine-Tuning Léger des modèles IA
Pour des domaines très spécifiques où les LLM génériques peinent, un fine-tuning léger sur un petit corpus de données de haute qualité peut améliorer la pertinence et réduire les hallucinations. Cependant, cela doit être fait avec prudence pour éviter l'overfitting et la perte de généralisation.
2. Détecter les hallucinations LLM en production
La détection vise à identifier les hallucinations une fois qu'elles ont été générées, avant qu'elles n'atteignent l'utilisateur final ou un système critique.
Exigence de citations : Traçabilité des modèles IA
Pour les réponses factuelles, exiger du LLM qu'il cite explicitement les passages des documents sources qui justifient chaque affirmation. Cela permet une vérification rapide et met en évidence les affirmations non sourcées, potentiellement hallucinées.
Scores de confiance des modèles LLM
Certains LLM peuvent fournir un score de confiance ou une mesure d'entropie pour leurs réponses. Un score bas ou une entropie élevée indique que le modèle est incertain de sa réponse, signalant un risque accru d'hallucination. Ces signaux peuvent déclencher une révision humaine ou un routage vers un autre système.
Vérification automatique : NLI et fact-checking IA
Utiliser des modèles NLI (Natural Language Inference) ou des systèmes de fact-checking automatisés pour comparer la réponse du LLM avec des bases de connaissances fiables ou les documents sources. Ces systèmes peuvent déterminer si la réponse est en contradiction, en déduction logique ou neutre par rapport aux faits établis.
Détection hors-Domaine des modèles LLM
Mettre en place des mécanismes pour identifier si la réponse du LLM sort du périmètre thématique attendu ou si elle aborde des sujets non autorisés. Cela peut être réalisé par des classificateurs de texte ou des listes de mots-clés.
Tests de règles métier pour les LLM Entreprise
Définir des règles métier spécifiques (un prix ne peut pas être négatif, une date de livraison ne peut pas être antérieure à la date de commande) et les appliquer aux sorties du LLM. Toute violation de ces règles signale une potentielle hallucination ou une erreur logique.
3. Corriger et orchestrer : stratégies post-hallucination
Une fois les hallucinations détectées, des mécanismes de correction et d'orchestration sont nécessaires pour gérer la situation de manière appropriée.
Auto-critique des modèles LLM
Le LLM peut être invité à revoir sa propre réponse, à identifier les incohérences ou les affirmations non sourcées, et à les corriger. Cela implique souvent une seconde passe du modèle avec un prompt spécifique pour l'auto-évaluation.
Re-requête ciblée des modèles IA
Si une hallucination est détectée, le système peut reformuler la requête ou interroger le LLM avec des contraintes supplémentaires, en se basant sur les informations qui ont conduit à l'erreur. Cela permet d'obtenir une réponse plus précise.
Consensus et vote majoritaire des LLM
Pour les tâches critiques, il est possible de générer plusieurs réponses en parallèle (avec différents LLM ou différentes configurations du même LLM) et de sélectionner la réponse par vote majoritaire ou par consensus. Cela réduit la probabilité qu'une hallucination isolée soit retenue.
Routage vers systèmes déterministes
Pour les questions factuelles ou les tâches nécessitant une exactitude absolue (calculs, recherche de données spécifiques), le système peut router la requête vers une base de données, un système expert ou une API déterministe plutôt que de laisser le LLM générer la réponse.
Refus proactif des modèles IA
Si le niveau de confiance est trop bas, si la requête est ambiguë, ou si le risque d'hallucination est trop élevé, le système doit pouvoir refuser de répondre poliment et expliquer pourquoi. C'est une forme d'abstention proactive qui préserve la fiabilité du système.
Escalade humaine : supervision des LLM
Pour les cas complexes, critiques ou persistants, le système doit prévoir un mécanisme d'escalade vers un opérateur humain qui pourra prendre le relais, vérifier l'information et fournir la réponse correcte. Cela permet de maintenir la qualité du service et de collecter des données pour améliorer le système.
Logs et traçabilité des modèles IA
Il est essentiel de logger toutes les interactions, les réponses du LLM, les détections d'hallucinations, les actions de correction et les escalades. Cette traçabilité est indispensable pour l'audit, l'analyse des causes racines des hallucinations et l'amélioration continue du système.
Stratégies 2025 pour maîtriser les hallucinations LLM
Vigilance constante : déploiement des modèles IA en ETI
Les hallucinations des LLM représentent un défi persistant et majeur qui ne disparaîtra pas avec les prochaines générations de modèles . Bien que les performances s'améliorent constamment, la nature probabiliste fondamentale de ces systèmes garantit qu'un risque résiduel demeurera toujours présent. Cette réalité technique impose aux entreprises une approche rigoureuse et méthodique.
L'impératif d'une stratégie globale anti-hallucination
Les entreprises qui souhaitent tirer parti des LLM sans compromettre leur réputation, leur conformité réglementaire ou leurs opérations doivent développer une stratégie globale de maîtrise des hallucinations. Cette stratégie ne peut se limiter à l'espoir que "le modèle fonctionnera correctement" - elle doit intégrer dès la conception les trois piliers fondamentaux : prévention, détection et correction.
Les techniques présentées dans ce document - du RAG au contrôle de température, des schémas JSON à l'escalade humaine - ne sont pas des options facultatives mais des composants essentiels d'une architecture de production robuste. Leur mise en œuvre coordonnée permet de réduire significativement les risques tout en préservant les bénéfices attendus des LLM.
Tests pré-production : critères essentiels pour les LLM Entreprise
Aucune entreprise ne devrait déployer un système basé sur les LLM sans avoir mis en place une stratégie de test exhaustive et continue. Les benchmarks présentés offrent un point de départ, mais chaque organisation doit développer ses propres jeux de tests adaptés à ses cas d'usage spécifiques, ses données métier et ses contraintes opérationnelles.
Ces tests doivent couvrir non seulement les performances nominales, mais aussi les cas limites, les situations d'erreur et les scénarios de charge. Plus important encore, ils doivent être intégrés dans un processus d'amélioration continue, car les patterns d'hallucination évoluent avec l'usage et les modifications du système.
Investissement stratégique : ROI des modèles IA sans hallucination
La maîtrise des hallucinations représente un investissement technique et organisationnel conséquent, mais il s'agit du prix à payer pour déployer les LLM de manière responsable et efficace. Les entreprises qui négligent cet aspect s'exposent à des risques considérables : incidents de réputation, non-conformité réglementaire, perte de confiance des clients et coûts de correction exponentiels.
À l'inverse, celles qui investissent dès maintenant dans ces compétences et ces infrastructures se positionnent avantageusement pour exploiter pleinement le potentiel transformateur des LLM, tout en maintenant les standards de qualité et de fiabilité que leurs parties prenantes attendent légitimement.
L'enjeu n'est plus de savoir si les entreprises utiliseront les LLM, mais comment elles le feront de manière maîtrisée et durable. La gestion des hallucinations constitue la clé de voûte de cette réussite.